
Il GEO Score: Come si misura se un sito è pronto per l'era dei Motori Generativi
Ogni fase della visibilità digitale ha avuto la propria metrica dominante.
Per molti anni il PageRank ha rappresentato uno dei modi con cui Google misurava l’autorevolezza di una pagina: un modello capace di leggere la fiducia che il web esprimeva attraverso i link in entrata. Ha funzionato perché misurava un segnale reale, in un ecosistema in cui i link erano ancora una buona approssimazione dell’autorità.
La Domain Authority di Moz è arrivata dopo, quando l’industria SEO ha avuto bisogno di un indicatore leggibile e operativo per stimare quella stessa forza. Per anni, in una forma o nell’altra, posizionarsi ha significato accumulare segnali esterni: link, menzioni, dominio, reputazione.
Il web generativo cambia il campo di gioco.
ChatGPT, Claude, Perplexity, Gemini e Copilot non mostrano semplicemente una lista di risultati. Producono risposte, selezionano fonti, sintetizzano contenuti, citano alcuni brand e ne ignorano altri. In questo contesto, la visibilità non coincide più solo con la posizione in SERP. Conta anche se un brand entra nella risposta generata, con quali fonti accanto, in quale contesto e con quale grado di autorevolezza percepita.
Per questo serve un modello di scoring diverso. PageRank e Domain Authority continuano a misurare segnali importanti, ma appartengono a una logica costruita intorno al ranking delle pagine. Il GEO Score nasce invece per misurare la preparazione di un sito rispetto ai motori generativi: quanto è leggibile, quanto è coerente, quanto è autorevole, quanto è citabile.
Questo articolo racconta la logica del nostro GEO Score, il modello al centro dello scoring engine di GeoSonar. Non come claim di marketing, ma come modello tecnico: tre pilastri, sedici sotto-metriche, tecniche GEO derivate dalla ricerca accademica, blueprint per verticale di business e una formula esplicita, leggibile e riproducibile.
Il GEO Score nasce da questa idea: se la visibilità cambia forma, anche il modo di misurarla deve cambiare.
Un Problema di Misurazione
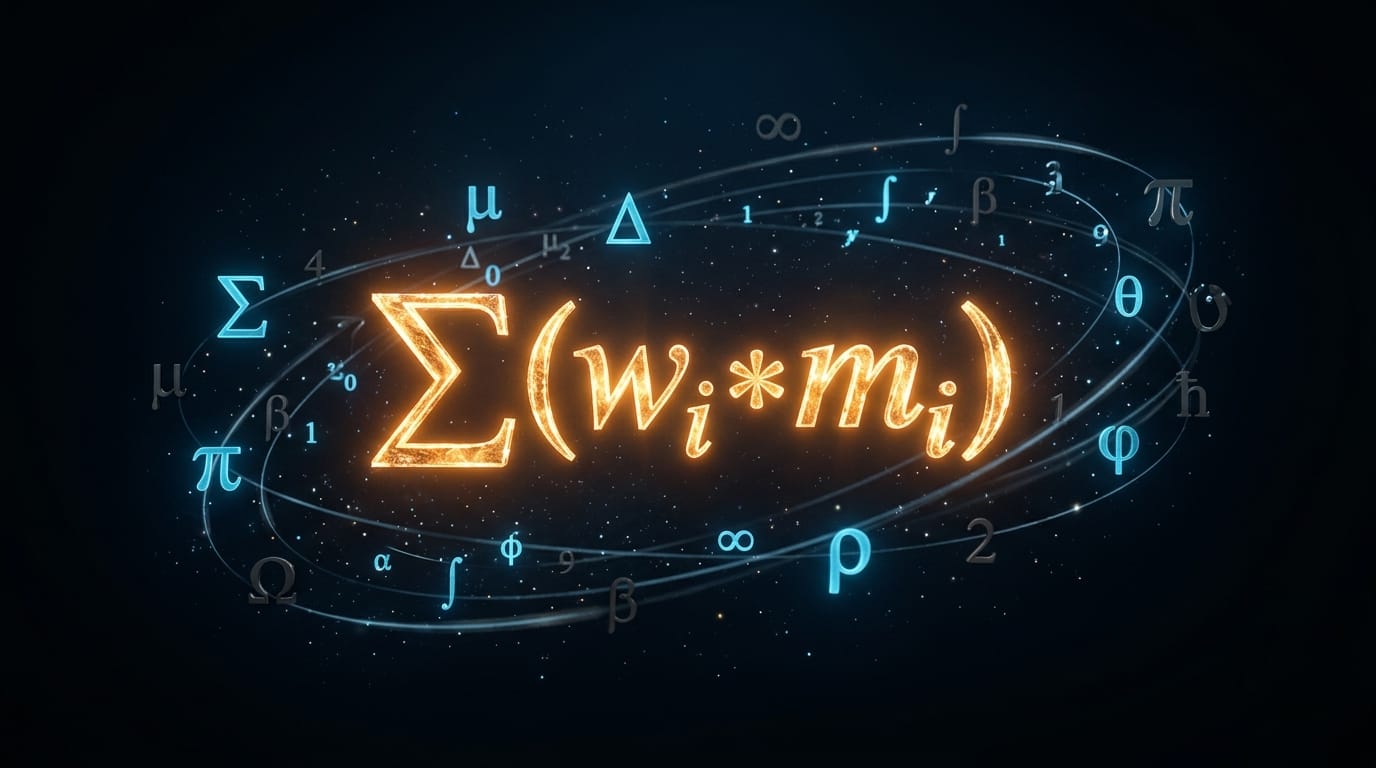
Prima della metrica, c’è il problema da misurare.
Se chiedi a ChatGPT quali siano le migliori piattaforme SaaS per la contabilità di una PMI italiana, il modello ti restituisce una risposta sintetica e cita alcuni prodotti. Ma perché proprio quelli? Quali fonti ha considerato? Quali brand ha escluso? E se sei il fondatore di un prodotto altrettanto valido, ma assente dalla risposta, che cosa puoi fare concretamente?
Le metriche SEO classiche non bastano a rispondere a queste domande, perché il problema è cambiato.
Il primo punto è l’opacità. Non esiste una dashboard pubblica e condivisa che dica a un brand quale motore generativo lo cita, quale lo ignora, con quale frequenza e per quali query.
Il secondo è la differenza tra motori. ChatGPT, Perplexity, Claude, Gemini e Copilot non selezionano sempre le stesse fonti, non costruiscono le risposte nello stesso modo e non danno lo stesso peso agli stessi segnali. Ogni motore ha logiche proprie di ricerca, citazione e sintesi, che vanno osservate separatamente.
Il terzo è la riproducibilità. Un audit manuale può cambiare a seconda del momento, del prompt, del consulente, del motore interrogato e della formulazione della query. Se il metodo non è stabile, il risultato diventa difficile da confrontare nel tempo e tra clienti diversi.
Il GEO Score nasce per affrontare questi tre problemi insieme. Il motore di scoring è deterministico: scansiona il sito, estrae HTML, JSON-LD, contenuti testuali e blocchi strutturati, poi valuta i segnali con regole, euristiche, espressioni regolari multilingua e fuzzy matching. L’LLM non decide mai liberamente il punteggio: interviene solo nei casi realmente ambigui e soprattutto nella generazione di insight, raccomandazioni e report narrativi a partire da risultati già calcolati.
Il modello è configurabile per verticale di business, perché un e-commerce non vive sugli stessi segnali di un publisher editoriale. Ed è ricostruibile: ogni valore può essere ricondotto alle sue componenti fondamentali, ai suoi pesi e alle evidenze che lo hanno prodotto.
Il Modello a Tre Pilastri

L’intuizione di fondo del motore è che la visibilità AI non sia una cosa sola. È il risultato di tre dimensioni diverse: la leggibilità tecnica del sito, la qualità narrativa dei contenuti e l’autorità percepita dall’esterno.
graph TD
GEO[GEO Score Complessivo<br/>0 – 100]
GEO --> INFRA[Infrastructure<br/>peso 0.30]
GEO --> NARR[Narrative<br/>peso 0.35]
GEO --> AUTH[Authority<br/>peso 0.35]Infrastructure, peso 0,30, è la base tecnica. Il sito è raggiungibile? I crawler AI possono leggerlo? Gli schema JSON-LD sono ben formati? La sitemap è valida? Un sito tecnicamente invisibile difficilmente può essere citato, anche quando il contenuto è valido.
Narrative, peso 0,35, misura la qualità e la coerenza dei contenuti. Il sito copre gli argomenti chiave del business? È coerente con il posizionamento dichiarato del brand? Implementa tecniche GEO derivate dalla ricerca accademica? Un sito con infrastruttura solida ma contenuti deboli può essere letto, ma non necessariamente scelto.
Authority, peso 0,35, misura la validazione esterna. Il brand è menzionato su piattaforme social e fonti autorevoli? È presente su piattaforme di recensione come G2, Capterra o Trustpilot? Viene già citato dai motori AI nelle query branded? Un sito con buoni contenuti, ma senza segnali esterni di autorevolezza, fatica di più a entrare nelle risposte generate.
La scelta di assegnare il 70% del peso a Narrative e Authority, e il 30% a Infrastructure, riflette una convinzione precisa alla base del modello: l’infrastruttura rende il sito leggibile, ma non basta a renderlo citabile. Nei motori generativi, contano anche la qualità del contenuto, la chiarezza delle evidenze, la ricchezza informativa e i segnali esterni che rendono una fonte più affidabile di un’altra.
Le Sedici Sotto-Metriche

Ogni pilastro è scomposto in un numero contenuto di sotto-metriche, scelte per essere misurabili oggettivamente e non ridondanti. Cinque per Infrastructure, cinque per Narrative, sei per Authority. Sedici in totale. Ciascuna su scala 0–100.
Infrastructure — il Sostrato Tecnico
| Sotto-metrica | Peso base | Cosa misura |
|---|---|---|
| structural_presence | 0.20 | Title, description, sitename, Open Graph, meta tag fondamentali |
| technical_accessibility | 0.20 | Homepage raggiungibile, HTTPS attivo, tempo di risposta |
| structured_data | 0.25 | Quantità e qualità degli schema JSON-LD (Organization, Product, Article) |
| crawlability | 0.20 | robots.txt, sitemap, bot AI autorizzati (oltre 80 crawler classificati per tier) |
| site_architecture | 0.15 | Profondità pagine, struttura URL, linking interno |
Il peso maggiore va a structured_data (0,25). Non è casuale: i dati strutturati aiutano i sistemi di ricerca e interpretazione a riconoscere entità, prodotti, organizzazioni e relazioni senza dipendere solo dal testo libero. Un sito con schema Product ben formato offre segnali più espliciti su prodotto, prezzo, disponibilità e caratteristiche rispetto a una pagina che affida tutto al testo libero.
Il punto più delicato è la crawlability. Il motore non misura solo se il bot di Google può entrare: mantiene un registro di oltre ottanta crawler AI classificati per tier — da GPTBot di OpenAI a ClaudeBot di Anthropic a PerplexityBot. Un sito che blocca selettivamente alcuni bot può ridurre la propria accessibilità per interi ambienti di ricerca e risposta generativa, e il punteggio lo riflette.
Narrative — la Qualità del Contenuto
| Sotto-metrica | Peso base | Cosa misura | Metodo |
|---|---|---|---|
| completeness | 0.20 | Copertura degli argomenti chiave per verticale (pricing, target, differenziatori) | Hybrid euristico + LLM |
| coherence | 0.15 | Coerenza tra sito e input del progetto | Hybrid fuzzy matching + DSPy |
| semantic_alignment | 0.25 | Allineamento tra input progettuali e percezione AI del brand | Hybrid overlap + LLM judge |
| factual_density | 0.15 | Schema strutturati + keyword con volume di ricerca | Heuristic |
| geo_method_score | 0.25 | Implementazione delle 8 tecniche GEO di Princeton | Heuristic audit |
La valutazione Narrative utilizza un approccio ibrido euristico + LLM: ogni metrica viene prima calcolata con algoritmi deterministici (keyword matching, fuzzy matching con rapidfuzz), e solo nei casi ambigui — quando il punteggio cade in una zona grigia prestabilita — viene attivata una valutazione LLM via DSPy ChainOfThought per disambiguare. È una scelta ingegneristica precisa: l'euristica dà riproducibilità e velocità, l'LLM dà finezza dove serve davvero.
Mai l'LLM da solo, perché non è riproducibile.
Mai l'euristica da sola, perché non distingue le sfumature.
Il peso più alto va a semantic_alignment e geo_method_score, entrambi a 0,25. Il primo misura la distanza tra come il brand si descrive e come gli AI lo descrivono. Un disallineamento alto, per esempio tra un brand che si presenta come soluzione enterprise e un motore AI che lo descrive come tool per freelance, può compromettere la rappresentazione del brand nelle risposte generate, anche quando i segnali SEO tradizionali sembrano buoni.
Authority — la Validazione Esterna
| Sotto-metrica | Peso base | Cosa misura |
|---|---|---|
| external_mentions | 0.15 | Menzioni social verificate (X, Reddit, YouTube, LinkedIn, Wikipedia) |
| reviews_rating | 0.15 | Review su G2, Capterra, Trustpilot, TrustRadius |
| competitive_visibility | 0.15 | Tasso di citazione del brand nelle query branded |
| backlink_quality | 0.15 | Qualità dei domini referenti |
| industry_authority | 0.20 | Percentuale di piattaforme di review verificate |
| discovery_citation_rate | 0.20 | Citazione per-engine sulle query discovery (non-branded) |
I due pesi più alti — industry_authority e discovery_citation_rate (0,20 entrambi) — riflettono una scelta strategica. Essere presente sulle piattaforme di review giuste è un segnale strutturale: non stai solo esistendo, stai partecipando al tessuto editoriale del tuo settore. E il discovery rate su query non-branded misura la cosa più importante di tutte: quando l'utente NON cerca te, i motori ti trovano comunque? È uno dei segnali più importanti della maturità GEO.
La Formula

Il calcolo del GEO Score resta volutamente semplice e leggibile. Per ogni pilastro, il motore somma le sotto-metriche applicando a ciascuna il proprio peso:
P_pillar = Σ (w_i × m_i)dove w_i è il peso della sotto-metrica i e m_i è il suo valore in 0–100. I pesi sommano sempre a 1,0 dopo normalizzazione.
Il GEO Score complessivo è la somma pesata dei tre pilastri:
GEO Score = 0.30 × P_infra + 0.35 × P_narr + 0.35 × P_authSemplice. E intenzionalmente semplice. Una formula complessa con fattori correttivi non-lineari potrebbe guadagnare qualche punto di precisione su benchmark specifici, ma perderebbe due proprietà che valgono più di quella precisione: la comprensibilità — chiunque può ricalcolare il punteggio a mano e capire perché è alto o basso — e la stabilità — non ci sono discontinuità dove un miglioramento minuscolo produce un salto enorme.
Un Esempio Concreto
Applicando il motore a un audit reale di xyz.ai (blueprint SaaS):
Infrastructure — contributi alle sotto-metriche: structural_presence 100, technical_accessibility 100, structured_data 25, crawlability 100, site_architecture 38. Totale pilastro: 68.3.
Narrative — completeness 47, coherence 80, semantic_alignment 50, factual_density 100, geo_method_score 43. Totale: 58.8.
Authority — quasi tutte le sotto-metriche a 0, solo competitive_visibility a 40. Totale: 7.3.
GEO Score = 0.30 × 68.3 + 0.35 × 58.8 + 0.35 × 7.3 = 20.5 + 20.6 + 2.6 = 43.6Tier complessivo: POOR. Il punteggio racconta una storia coerente: infrastruttura tecnica solida, contenuto accettabile ma migliorabile, autorità esterna praticamente assente. La priorità di intervento si legge ad occhio: costruire authority. E il detector suggerisce dove — review platform, menzioni, discovery rate per motore.
Le Otto Tecniche GEO di Princeton
Dentro la metrica geo_method_score vive una delle parti più interessanti del motore. I GEO Methods sono le otto tecniche di ottimizzazione editoriale derivate dalla ricerca accademica GEO: Generative Engine Optimization di Aggarwal e colleghi (Princeton, KDD '24). Ogni tecnica ha un boost base e un moltiplicatore che varia in base alla posizione SERP del sito su Google.
graph TD
SERP[Posizione SERP del sito]
SERP --> HIGH{Posizione 1-10?}
HIGH -->|Sì| HI[Moltiplicatore 0.55-0.75<br/>impatto marginale]
HIGH -->|No| MID{Posizione 11-30?}
MID -->|Sì| MI[Moltiplicatore 1.0<br/>boost base invariato]
MID -->|No| LO[Moltiplicatore 1.60-2.88<br/>impatto massimo]
HI --> CALC[Impatto = base_boost × moltiplicatore]
MI --> CALC
LO --> CALC| Tecnica | Boost base | Rank 1-10 | Rank 11-30 | Rank 30+ |
|---|---|---|---|---|
| Cite Sources | 0.40 | 0.22 | 0.40 | 1.15 |
| Statistics | 0.37 | 0.22 | 0.37 | 0.93 |
| Quotations | 0.30 | 0.20 | 0.30 | 0.66 |
| Authoritative Tone | 0.25 | 0.16 | 0.25 | 0.50 |
| Technical Terms | 0.20 | 0.12 | 0.20 | 0.42 |
| Unique Terminology | 0.18 | 0.13 | 0.18 | 0.34 |
| Fluency Optimization | 0.15 | 0.11 | 0.15 | 0.27 |
| Easy to Understand | 0.12 | 0.09 | 0.12 | 0.19 |
La logica del moltiplicatore codifica una delle scoperte più controintuitive del paper Princeton: se sei già primo su Google, le tecniche GEO aggiungono poco o addirittura ti danneggiano.
Quando un sito è già molto visibile su Google, il margine di miglioramento tende a essere più basso. Se invece si trova fuori dalle prime posizioni, dove la SEO classica fatica a portarlo in superficie ma i sistemi di retrieval dei motori generativi possono ancora intercettarlo, le stesse tecniche possono produrre un impatto molto più alto.
Il motore incorpora questa curva direttamente nel calcolo. Non genera una raccomandazione generica del tipo “aggiungi statistiche”. Calcola quanto una tecnica possa incidere su una pagina specifica, in una determinata posizione SERP. Su una pagina in posizione 18, ad esempio, Statistics può valere un boost di 0,37 e Cite Sources un boost di 0,40.
Per questo la priorità delle raccomandazioni cambia da sito a sito e da pagina a pagina.
I 9 Blueprint: stesso motore, pesi diversi
I blueprint servono a evitare una formula unica applicata indistintamente a contesti molto diversi. Un e-commerce, un publisher editoriale, un brand locale e un SaaS globale non dipendono dagli stessi segnali, né vengono valutati nello stesso modo dai motori generativi. Per questo il motore usa nove blueprint, ciascuno pensato per adattare pesi e priorità al tipo di attività analizzata:
| Blueprint | Tratto distintivo |
|---|---|
| SaaS | Peso alto su structured_data e geo_method_score |
| Enterprise | Peso su industry_authority e technical_accessibility |
| E-commerce | reviews_rating e structured_data dominano |
| B2C | Mix di external_mentions e reviews_rating |
| Publisher | external_mentions e industry_authority elevati; review quasi irrilevanti |
| Agency | industry_authority come differenziatore primario |
| Services | Bilanciamento tra contenuto e autorità professionale |
| Local Service | reviews_rating e structured_data al massimo |
| Base (default) | Pesi bilanciati quando il verticale è ignoto |
Ogni blueprint modifica solo i pesi che devono cambiare rispetto alla configurazione di base. Per un SaaS, ad esempio, non serve ridefinire tutte e sedici le sotto-metriche: basta indicare quali devono pesare di più o di meno rispetto al default. Il merge ricorsivo della configurazione combina queste variazioni con la base comune e, alla fine, normalizza automaticamente ogni sezione, mantenendo la somma dei pesi entro la soglia prevista.
Perché Local Service è Diverso
Il blueprint Local Service mostra bene perché i pesi non possono essere uguali per tutti i verticali.
Per un’attività locale, come un dentista, un idraulico o un ristorante, le recensioni hanno un peso molto più rilevante rispetto ad altri contesti. Nel blueprint Local Service, reviews_rating pesa 0,304, contro 0,150 della configurazione di base. In pratica, il segnale delle recensioni conta circa il doppio.
Il motivo è semplice: nelle ricerche locali, la fiducia passa spesso da segnali immediatamente verificabili, come numero di recensioni, qualità media, presenza su piattaforme riconosciute e coerenza delle informazioni disponibili online. Un’attività con molte recensioni credibili e distribuite su fonti affidabili offre ai motori generativi un segnale più solido rispetto a una presenza locale debole o poco documentata.
Per un Publisher editoriale, invece, lo stesso segnale conta molto meno. Il peso di reviews_rating scende a 0,048, perché un giornale, una rivista o un sito editoriale non costruiscono autorevolezza attraverso le recensioni su piattaforme come Trustpilot. In quel caso pesano di più le citazioni da altri media, le menzioni esterne, la riconoscibilità della testata e la presenza nel tessuto informativo del settore.
La formula resta la stessa, ma il punto di equilibrio cambia. Il blueprint serve proprio a questo: adattare lo scoring al tipo di realtà analizzata, senza cambiare il motore.
La Pipeline di Configurazione

Tecnicamente, tutto questo poggia su una pipeline a tre livelli con merge ricorsivo:
graph TD
L1[Livello 1: base.toml<br/>pesi di default]
L2[Livello 2: formulas/v1.toml<br/>override formula]
L3[Livello 3: blueprints/saas.toml<br/>override verticale]
L1 --> M1[Deep merge]
L2 --> M1
M1 --> M2[Deep merge]
L3 --> M2
M2 --> NORM[Normalizzazione<br/>somma pesi = 1.0]
NORM --> VAL[Validazione Pydantic]
VAL --> FROZEN[ScoringConfig<br/>dataclass immutabile]La configurazione finale è una dataclass frozen: immutabile, tipizzata, validata da Pydantic. Qualsiasi tentativo di calcolare un punteggio con parametri inconsistenti — pesi che non sommano a 1.0, soglie non decrescenti, tier sovrapposti — fallisce in fase di validazione, prima di produrre qualsiasi output.
La garanzia è strutturale, non fiduciaria.
Il Visibility Score: la Metrica Complementare
Accanto al GEO Score vive un punteggio separato che misura una cosa specifica e diversa: su quanti motori AI il brand viene citato nelle query branded e non.
Visibility = motori_che_citano × 20Con cinque motori (Perplexity, ChatGPT, Gemini, Claude, Copilot), ogni motore vale venti punti. Il massimo è cento.
| Motori che citano | Visibility | Lettura |
|---|---|---|
| 5 / 5 | 100 | Copertura completa |
| 3 / 5 | 60 | Buona, con gap |
| 2 / 5 | 40 | Parziale |
| 0 / 5 | 0 | Invisibile |
Il Visibility Score è intenzionalmente escluso dal GEO Score. Sono due metriche distinte perché misurano aspetti diversi dello stesso problema.
Il GEO Score misura il potenziale: quanto un sito è preparato per essere citato dai motori generativi. Il Visibility Score misura lo stato attuale: quanti motori lo citano davvero.
Un sito può avere un GEO Score alto e un Visibility Score basso. In quel caso, l’ottimizzazione è presente, ma il segnale non è ancora emerso nelle risposte generate. Può accadere anche il contrario: GEO Score basso e Visibility Score medio. In quel caso, il brand potrebbe beneficiare di autorevolezza accumulata nel tempo, ma senza una base solida il vantaggio rischia di ridursi.
Leggere insieme le due metriche permette di capire meglio dove si trova un brand nel proprio ciclo di maturità GEO.
L'Architettura del Motore
L'implementazione tecnica segue una separazione netta a due layer.
Layer 1 — Calculator puri: ogni funzione compute_* prende dati audit grezzi (dict crawler, social, citation) e produce (score, findings). Sono funzioni deterministiche nel senso forte: nessuno side effect, nessuna dipendenza da stato, nessuna latenza esterna. Un test di regressione è banale: stesso input → stesso output, always.
Layer 2 — Aggregation: prende le sedici sotto-metriche già calcolate come DataFrame Polars, applica la somma pesata per pilastro, calcola il punteggio complessivo, assegna i tier qualitativi. Tutto l'algebra avviene in Polars — velocissimo, vettoriale, con supporto nativo per batch da centinaia di migliaia di righe.
graph TD
INPUT[Input: audit JSON<br/>16 sotto-metriche]
LOAD[load_config<br/>formula + blueprint]
BUILD[build_metrics_row<br/>DataFrame Polars 1×16]
PILLARS[score_pillar × 3<br/>somma pesata per pilastro]
OVERALL[score_overall<br/>somma pesata 3 pilastri]
TIERS[assign_tier × 4<br/>tier per pilastro + overall]
OUTPUT[Output: DataFrame<br/>16 input + 3 pilastri + overall + 4 tier]
INPUT --> LOAD
LOAD --> BUILD
BUILD --> PILLARS
PILLARS --> OVERALL
OVERALL --> TIERS
TIERS --> OUTPUTChi integra il motore può chiamare direttamente Layer 2 se ha già calcolato le sotto-metriche, oppure usare Layer 1 per derivarle da dati grezzi. Non c'è accoppiamento forzato tra i due layer. È un prodotto componibile.
Serializzazione e Output
Il risultato può essere serializzato in quattro formati, ciascuno con un caso d'uso preciso:
- JSON — schema v1.0.0, per API e documentazione umana
- Parquet — con partizionamento opzionale per blueprint/tier, per storage e analisi a grandi volumi
- TOON — formato compatto per contesto LLM, 30–60% di risparmio token
- NDJSON — per streaming e append continuo
Il formato TOON merita una nota perché nasce per un uso diverso rispetto a JSON, Parquet o NDJSON. Non serve principalmente alla persistenza, né all’analisi colonnare, né allo streaming. Serve a passare dati strutturati a un LLM in una forma più compatta e leggibile, riducendo il numero di token quando il risultato dell’audit deve diventare contesto operativo per un agente.
Nel caso di GeoSonar, questo chiude il ciclo tra misurazione e azione: il motore calcola il GEO Score, il risultato strutturato alimenta un agente di raccomandazione, l’agente genera insight e azioni prioritarie, il brand interviene, e l’audit successivo misura se qualcosa è cambiato.
La Tiering Qualitativa

Ogni punteggio (pilastro o complessivo) viene classificato in un tier leggibile anche da chi non ha mai aperto un documento tecnico:
| Tier | Range | Significato operativo |
|---|---|---|
| Excellent | 90–100 | Il sito è una fonte primaria per i motori AI |
| Good | 70–89 | Buona visibilità, ottimizzazioni mirate |
| Fair | 50–69 | Margine di miglioramento significativo |
| Poor | 40–49 | Interventi urgenti |
| Critical | 0–39 | Il sito è invisibile ai motori AI |
Il tier serve a tradurre il punteggio in una lettura operativa. Un GEO Score di 67, da solo, dice poco a chi deve decidere dove intervenire. Un tier Fair è più leggibile: indica che il sito è presente nella conversazione AI, ma non ha ancora una posizione solida.
La forza dei tier sta qui: non sono etichette estetiche applicate al punteggio.
Le soglie sono calibrate su distribuzioni reali e rendono visibile la distanza tra uno stato e il successivo. Passare da Fair a Good non significa superare una soglia cosmetica, ma migliorare abbastanza segnali da cambiare davvero il profilo dell’audit.
In questo senso, il tier non semplifica il dato: lo rende più utile per decidere.
Le proprietà del GEO Scoring Engine

Il GEO Scoring Engine si basa su cinque proprietà progettuali: determinismo, trasparenza, fondamento metodologico, adattamento per verticale e componibilità.
Primo: è deterministico. A parità di sito analizzato, configurazione e dati estratti, il motore produce lo stesso risultato. Lo scoring non dipende da un LLM che interpreta liberamente il sito: parte da scraping, HTML, JSON-LD, contenuti strutturati, regex multilingua, euristiche e fuzzy matching. Ogni punto del punteggio può essere ricostruito partendo dai segnali rilevati.
Secondo: è trasparente. Formula, pesi e blueprint sono leggibili e ispezionabili. Chi vuole capire perché un sito ha ottenuto 43,6 e non 67 può leggere la configurazione, verificare le soglie e ricostruire il contributo di ogni sotto-metrica.
Terzo: è fondato su ricerca e su osservazioni operative. Le tecniche GEO derivano dal paper GEO: Generative Engine Optimization, pubblicato a KDD 2024. La struttura del motore incorpora anche evidenze più recenti sul comportamento dei sistemi generativi, sui pattern di citazione e sulle differenze tra ricerca tradizionale e AI search. La parte metodologica non nasce da opinioni generiche, ma da ricerca esistente e dati osservati negli audit.
Quarto: è adattato per verticale. I nove blueprint permettono di modificare i pesi in base al tipo di attività analizzata: SaaS, e-commerce, publisher, servizi, attività locali e altri contesti. Ogni blueprint riflette segnali diversi, perché non tutti i mercati costruiscono autorevolezza nello stesso modo.
Quinto: è componibile. Layer 1 e Layer 2 sono separati: si possono usare i calculator, il solo livello di aggregazione, oppure entrambi. Il risultato può essere serializzato in più formati, partizionato, analizzato in batch o usato in flussi incrementali. Il motore non impone un unico percorso di utilizzo.
La Visione di Fondo

La visione di fondo
Il GEO Score non serve ad aggiungere un numero elegante alla dashboard di un report. Serve a orientare decisioni.
Un brand che lo monitora nel tempo può capire in quale tier si trova, quali sotto-metriche stanno limitando la sua visibilità e quali interventi hanno priorità. Il punto non è solo sapere se il punteggio sale o scende, ma capire quali segnali stanno cambiando: infrastruttura tecnica, contenuto, autorità, citazioni, presenza sui motori, evidenze esterne.
In questo senso, il GEO Score non è una metrica isolata. È un modo per leggere la visibilità nei motori generativi come il risultato di scelte precise, ripetibili e misurabili. Non basta pubblicare contenuti buoni e aspettare che vengano trovati. Bisogna renderli leggibili, citabili, verificabili e coerenti con ciò che i motori generativi riescono effettivamente a interpretare.
PageRank ha dato al web dei link un feedback loop comprensibile: più segnali di fiducia, più possibilità di emergere. Il GEO Score nasce con una funzione simile per un contesto diverso: aiutare a capire quali segnali rendono un brand più o meno presente dentro una risposta generata.
Tre pilastri. Sedici sotto-metriche. Otto tecniche GEO. Nove blueprint. Una formula esplicita. Non per complicare la misurazione, ma per renderla ricostruibile.
Chi usa il GEO Score deve poter guardare i numeri, capire perché sono quelli e sapere dove intervenire. In un ecosistema in cui la visibilità tende a diventare sempre più opaca, questa scelta conta: non basta misurare, bisogna poter spiegare la misura.
Il GEO Score è quella posizione, espressa in matematica.
Riferimenti tecnici e metodologici
- PageRank originale
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- Google Search ranking systems
- Moz Domain Authority
- Google AI Overviews
- ChatGPT Search
- Claude Web Search
- Perplexity Search API
- GEO: Generative Engine Optimization
- GEO: Generative Engine Optimization, arXiv
- Structural Feature Engineering for Generative Engine Optimization
- E-GEO: A Testbed for Generative Engine Optimization in E-Commerce
- From Experience to Skill: Multi-Agent Generative Engine Optimization
- Citation patterns in AI search
- Verifiability in generative search
- Generative search vs traditional search
- Citation selection and absorption
- AI citation audit
- Google structured data introduction
- Google Product structured data
- OpenAI crawlers and bots
- Robots Exclusion Protocol, RFC 9309
- Robots.txt compliance study
- Robots.txt and AI crawlers
- Robots.txt legal limits
- JSON, RFC 8259
- JSON official site
- JSON Lines
- Apache Parquet documentation
- Apache Parquet file format
- Apache Parquet format repository
- Dremel paper
- Dremel made simple with Parquet
- Columnar formats evaluation
- TOON specification
- TOON official site
- TOON reference specification
- TOON repository
- TOON benchmark paper



Vero Dall'Aglio
I am a Principal AI Systems Architect with a background in designingand leading complex, production-grade software systems at theintersection of agentic AI, voice AI, and large-scale data platforms.